Understanding Big and Little Endian Byte Order
There are two different methods for describing the order in which a sequence of bytes are stored in digital systems:
- Big Endian: places the most significant byte first (also known as network byte order)
- Little Endian: places the least significant byte first
Etymology
The term endian comes from the novel Gulliver’s Travels by Jonathan Swift. In this fictitious world there were two island nations, Lilliput and Blefuscu. They were mortal enemies because the emperor of Lilliput had decreed that boiled eggs were to be cracked at the “little end”, whereas on Blefuscu they had always cracked their eggs at the “big end”. This seemingly trivial controversy had led to ongoing war between the two empires during which many thousands had been killed. It illustrates the fact that something quite simple can be done in two completely different ways.
Danny Cohen wrote a technical publication in 1980 entitled “On Holy Wars and a Plea for Peace” in which he reused the terms in the context of computing and telecommunication. He discussed the order that individual bytes within a larger ‘word’ (unit of data) can be stored and transmitted. He explained the issue of deciding whether the little end or the big end should come first. He ended his article with:
It may be interesting to notice that the point which Jonathan Swift tried to convey in Gulliver’s Travels is exactly the opposite of the point of this note. Swift’s point is that the difference between breaking the egg at the little-end and breaking it at the big-end is trivial. Therefore, he suggests, that everyone does it in his own preferred way. We agree that the difference between sending eggs with the little, or the big-end first is trivial, but we insist that everyone must do it in the same way, to avoid anarchy. Since the difference is trivial we may choose either way, but a decision must be made.
Digital Forensic Analysis
To fully understand and interpret data correctly, it is important to understand how data is stored. Digital forensic examiners have to understand the byte order concept so that they can correctly interpret the data they encounter during a forensic examination. Unfortunately, it is highly likely that both formats will be encountered on a regular basis.
The term ‘endian’ as derived from ‘end’ may lead to confusion. The end denotes which end of the number comes first rather than which part comes at the end of the sequence of bytes. The basic endian layout can be seen in the table below:

Base 10 Numbers
To understand this and get a handle on endianness, we will start with number base ten. Our decimal number system is typically written in big endian format. Numbers are placed so that the most significant (largest) values are located to the left and the least significant (smallest) to the right; therefore, when moving across the number from left to right, the most significant values are encountered first. As the number increases in value, we move from the least significant digit on the right to the left, each digit we add is worth ten times the previous digit. These positions are commonly known as units, tens, hundreds, thousands and so on. The weighted values for each position (up to one million) is as follows:

The number 3265 is easy to understand in decimal terms. It is made up as follows:
(3 x 1000) + (2 x 100) + (6 x 10) + (5 x 1)
When creating a number, we start with the units and add further digits as needed to create the number we want. For more information on number bases, see our introductory article: Introduction to Number Systems.
Base 16 Hex Numbers
When we look at hexadecimal data, the terms big endian and little endian refer to which bytes are most significant in multi-byte data types; they describe the order in which a sequence of bytes is stored. Numbers can be stored as a sequence of one or more bytes. To correctly evaluate a number from a sequence of bytes, we must know which system was used to store the values. For single byte stored values, the issue of endianness does not arise as the values are the same in both systems. The following shows some examples of integers stored in little and big endian format.

In the byte sequence above, the two highlighted bytes represent a 16 bit integer (8 bit x 2 = 16 bits or 2 bytes). We will look at their representation in both big and little endian format.
Big Endian
In hex, using 16 bits, the weighted value for each position is as follows:

In big endian format, the number 012316 would be calculated as follows:
(0 x 4096) + (1 x 256) + (2 x 16) + (3 x 1) = 29110
In hex, this number would be represented as 12316 (or 0x0123).
Little Endian
In hex, using 16 bits, the weighted value for each position is as follows:

In little endian format, the value would be calculated as follows:
(0 x 16) + (1 x 1) + (2 x 4096) + (3 x 256) = 896110
In hex, this number would be represented as 230116 (or 0x2301).
The important thing to remember is that the endianness describes the order in which a sequence of bytes are stored. Each byte is made up of two digits which represents the upper or lower 4 bits of the value. In this case, these digits do not change order, only the position of the actual byte.
32 bit Calculation
If the value was a 32 bit integer (8 bit x 4 = 32 bits or 4 bytes) instead of a 16 bit integer, the results would be slightly different. The image below shows the same sequence of bytes, but in this case, we will calculate the values from a 4 byte value instead of 2.

Big Endian
In hex, using 32 bits, the weighted value for each position is as follows:

In big endian format, the number 123000016 would be calculated as follows:
(0 x 268435456) + (1 x 16777216) + (2 x 1048576) + (3 x 65536) = 1907097610
In hex, this number would be represented as 123000016 (or 0x01230000).
Little Endian
In hex, using 32 bits, the weighted value for each position is as follows:

In little endian format, the value would be calculated as follows:
(0 x 16) + (1 x 1) + (2 x 4096) + (3 x 256) = 896110
In hex, this number would be represented as 230116 (or 0x00002301). The leading zeros would normally be dropped as their presence makes no difference to the numeric value; however, they do help to indicate the value is stored as a 32 bit integer.
Big and Little Endian Text Encoding
Another aspect of endianness which seems to cause confusion are the different methods for encoding and storing multi-byte characters. In the following examples, we will use the Notepad application to save a small text file in big and little endian UTF-16 format and then examine the file in a hex viewer. For a primer on character encoding, see our introductory article: Character Encoding: A Quick Primer.
Little Endian UTF-16 Text
In the image below, we can see the text represented by different UTF-16 code points, displayed in hex format. In this case, the text is stored in little endian format.
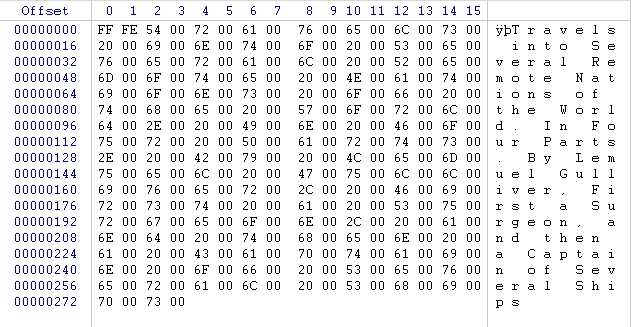
The first two bytes FF FE represent a byte order mark (BOM). Byte order marks describe the endianness of a text stream and the encoding used. With UTF-16, each character uses two or more bytes.
With standard ASCII encoded as UTF-16, we can see that each character in the text above only requires two bytes. In the case of little endian format, the least significant byte appears first, followed by the most significant byte. The letter ‘T’ has a value of 0x54 and is represented in 16 bit little endian as 54 00.
Big Endian UTF-16 Text
In the image below, we can see the text represented by different UTF-16 code points, displayed in hex format. In this case, the text is stored in big endian format.
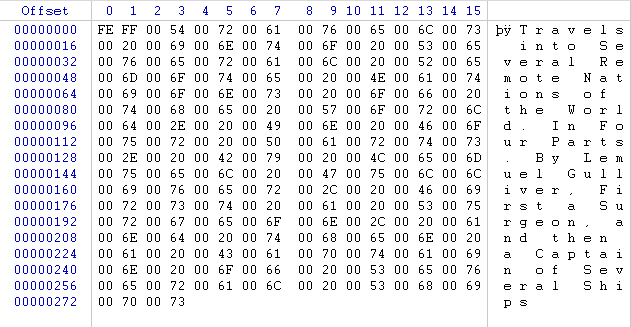
As with the previous example, the text stream starts with a byte order mark FE FF. This indicates a UTF-16 stream in big endian format. As this text is stored in big endian format, the most significant byte is encountered first in each two byte character. The letter ‘T’ has a value of 0x54 and is represented in 16 bit big endian as 00 54.
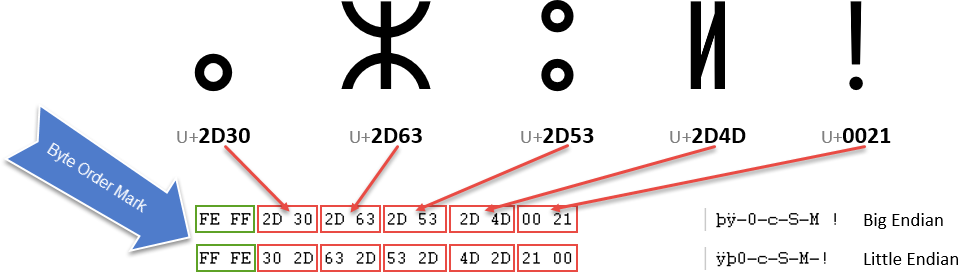
The image below shows the bytes used in a sequence of two byte characters. Each two digit hex number represents a byte in the stream of text. You can see that the order of the two bytes that represent a single character is reversed for big endian vs. little endian storage. The byte order mark indicates which order is used so that applications can decode the content.
Endianness of Common File Formats
The following list highlights the endianness of some common file formats:
- BMP – Little Endian
- GIF – Little Endian
- JPEG – Big Endian
- MPEG-4 – Big Endian
- PNG – Big Endian
- TIFF – Both, Endian identifier encoded into file
Further Reading
Other articles in our core knowledge series for learning digital forensics: